NAG Library Chapter Introduction
g02 – Correlation and Regression Analysis
1 Scope of the Chapter
This chapter is concerned with two techniques – correlation analysis and regression modelling – both of which are concerned with determining the inter-relationships among two or more variables.
Other chapters of the NAG C Library which cover similar problems are
Chapters e02 and
e04.
Chapter e02 functions may be used to fit linear models by criteria other than least squares, and also for polynomial regression;
Chapter e04 functions may be used to fit nonlinear models and linearly constrained linear models.
2 Background to the Problems
2.1 Correlation
2.1.1 Aims of correlation analysis
Correlation analysis provides a single summary statistic – the correlation coefficient – describing the strength of the association between two variables. The most common types of association which are investigated by correlation analysis are linear relationships, and there are a number of forms of linear correlation coefficients for use with different types of data.
2.1.2 Correlation coefficients
The (Pearson) product-moment correlation coefficients measure a linear relationship, while Kendall's tau and Spearman's rank order correlation coefficients measure monotonicity only. All three coefficients range from to . A coefficient of zero always indicates that no linear relationship exists; a coefficient implies a ‘perfect’ positive relationship (i.e., an increase in one variable is always associated with a corresponding increase in the other variable); and a coefficient of indicates a ‘perfect’ negative relationship (i.e., an increase in one variable is always associated with a corresponding decrease in the other variable).
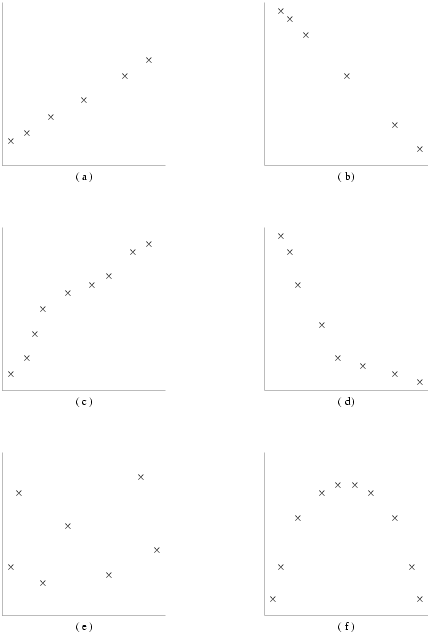
Consider the bivariate scattergrams in
Figure 1: (a) and (b) show strictly linear functions for which the values of the product-moment correlation coefficient, and (since a linear function is also monotonic) both Kendall's tau and Spearman's rank order coefficients, would be
and
respectively. However, though the relationships in figures (c) and (d) are respectively monotonically increasing and monotonically decreasing, for which both Kendall's and Spearman's nonparametric coefficients would be
(in (c)) and
(in (d)), the functions are nonlinear so that the product-moment coefficients would not take such ‘perfect’ extreme values. There is no obvious relationship between the variables in figure (e), so all three coefficients would assume values close to zero, while in figure (f) though there is an obvious parabolic relationship between the two variables, it would not be detected by any of the correlation coefficients which would again take values near to zero; it is important therefore to examine scattergrams as well as the correlation coefficients.
In order to decide which type of correlation is the most appropriate, it is necessary to appreciate the different groups into which variables may be classified. Variables are generally divided into four types of scales: the nominal scale, the ordinal scale, the interval scale, and the ratio scale. The nominal scale is used only to categorise data; for each category a name, perhaps numeric, is assigned so that two different categories will be identified by distinct names. The ordinal scale, as well as categorising the observations, orders the categories. Each category is assigned a distinct identifying symbol, in such a way that the order of the symbols corresponds to the order of the categories. (The most common system for ordinal variables is to assign numerical identifiers to the categories, though if they have previously been assigned alphabetic characters, these may be transformed to a numerical system by any convenient method which preserves the ordering of the categories.) The interval scale not only categorises and orders the observations, but also quantifies the comparison between categories; this necessitates a common unit of measurement and an arbitrary zero-point. Finally, the ratio scale is similar to the interval scale, except that it has an absolute (as opposed to arbitrary) zero-point.
For a more complete discussion of these four types of scales, and some examples, you are referred to
Churchman and Ratoosh (1959) and
Hays (1970).
Figure 1
Product-moment correlation coefficients are used with variables which are interval (or ratio) scales; these coefficients measure the amount of spread about the linear least squares equation. For a product-moment correlation coefficient,
, based on
pairs of observations, testing against the null hypothesis that there is no correlation between the two variables, the statistic
has a Student's
-distribution with
degrees of freedom; its significance can be tested accordingly.
Ranked and ordinal scale data are generally analysed by nonparametric methods – usually either Spearman's or Kendall's tau rank order correlation coefficients, which, as their names suggest, operate solely on the ranks, or relative orders, of the data values. Interval or ratio scale variables may also be validly analysed by nonparametric methods, but such techniques are statistically less powerful than a product-moment method. For a Spearman rank order correlation coefficient,
, based on
pairs of observations, testing against the null hypothesis that there is no correlation between the two variables, for large samples the statistic
has approximately a Student's
-distribution with
degrees of freedom, and may be treated accordingly. (This is similar to the product-moment correlation coefficient,
, see above.) Kendall's tau coefficient, based on
pairs of observations, has, for large samples, an approximately Normal distribution with mean zero and standard deviation
when tested against the null hypothesis that there is no correlation between the two variables; the coefficient should therefore be divided by this standard deviation and tested against the standard Normal distribution,
.
When the number of ordinal categories a variable takes is large, and the number of ties is relatively small, Spearman's rank order correlation coefficients have advantages over Kendall's tau; conversely, when the number of categories is small, or there are a large number of ties, Kendall's tau is usually preferred. Thus when the ordinal scale is more or less continuous, Spearman's rank order coefficients are preferred, whereas Kendall's tau is used when the data is grouped into a smaller number of categories; both measures do however include corrections for the occurrence of ties, and the basic concepts underlying the two coefficients are quite similar. The absolute value of Kendall's tau coefficient tends to be slightly smaller than Spearman's coefficient for the same set of data.
There is no authoritative dictum on the selection of correlation coefficients – particularly on the advisability of using correlations with ordinal data. This is a matter of discretion for you.
2.1.3 Partial correlation
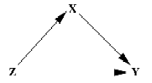
The correlation coefficients described above measure the association between two variables ignoring any other variables in the system. Suppose there are three variables
and
as shown in the path diagram below.
Figure 2
The association between
and
is made up of the direct association between
and
and the association caused by the path through
, that is the association of both
and
with the third variable
. For example if
and
were cholesterol level and blood pressure and
were age since both blood pressure and cholesterol level may increase with age the correlation between blood pressure and cholesterol level eliminating the effect of age is required.
The correlation between two variables eliminating the effect of a third variable is known as the partial correlation. If
,
and
represent the correlations between
,
and
then the partial correlation between
and
given
is
The partial correlation is then estimated by using product-moment correlation coefficients.
In general, let a set of variables be partitioned into two groups
and
with
variables in
and
variables in
and let the variance-covariance matrix of all
variables be partitioned into
Then the variance-covariance of
conditional on fixed values of the
variables is given by
The partial correlation matrix is then computed by standardizing
.
2.1.4 Robust estimation of correlation coefficients
The product-moment correlation coefficient can be greatly affected by the presence of a few extreme observations or outliers. There are robust estimation procedures which aim to decrease the effect of extreme values.
Mathematically these methods can be described as follows. A robust estimate of the variance-covariance matrix,
, can be written as
where
is a correction factor to give an unbiased estimator if the data is Normal and
is a lower triangular matrix. Let
be the vector of values for the
th observation and let
,
being a robust estimate of location, then
and
are found as solutions to
and
where
,
and
are functions such that they return a value of
for reasonable values of
and decreasing values for large
. The correlation matrix can then be calculated from the variance-covariance matrix. If
,
, and
returned
for all values then the product-moment correlation coefficient would be calculated.
2.1.5 Missing values
When there are missing values in the data these may be handled in one of two ways. Firstly, if a case contains a missing observation for any variable, then that case is omitted in its entirety from all calculations; this may be termed casewise treatment of missing data. Secondly, if a case contains a missing observation for any variable, then the case is omitted from only those calculations involving the variable for which the value is missing; this may be called pairwise treatment of missing data. Pairwise deletion of missing data has the advantage of using as much of the data as possible in the computation of each coefficient. In extreme circumstances, however, it can have the disadvantage of producing coefficients which are based on a different number of cases, and even on different selections of cases or samples; furthermore, the ‘correlation’ matrices formed in this way need not necessarily be positive semidefinite, a requirement for a correlation matrix. Casewise deletion of missing data generally causes fewer cases to be used in the calculation of the coefficients than does pairwise deletion. How great this difference is will obviously depend on the distribution of the missing data, both among cases and among variables.
Pairwise treatment does therefore use more information from the sample, but should not be used without careful consideration of the location of the missing observations in the data matrix, and the consequent effect of processing the missing data in that fashion.
2.1.6 Nearest Correlation Matrix
A correlation matrix is, by definition, a symmetric, positive semidefinite matrix with unit diagonals and all elements in the range .
In practice, rather than having a true correlation matrix, you may find that you have a matrix of pairwise correlations. This usually occurs in the presence of missing values, when the missing values are treated in a pairwise fashion as discussed in
Section 2.1.5. Matrices constructed in this way may not be not positive semidefinite, and therefore are not a valid correlation matrix. However, a valid correlation matrix can be calculated that is in some sense ‘close’ to the original.
Given an
matrix,
, there are a number of available ways of computing the ‘nearest’ correlation matrix,
to
:
| (a) |
Frobenius Norm
Find such that
is minimized. Where is the symmetric matrix defined as and and denotes the elements of and respectively.
A weighted Frobenius norm can also be used. The term being summed across therefore becomes
if row and column weights are being used or
when element-wise weights are used.
|
| (b) |
Factor Loading Method
This method is similar to (a) in that it finds a that is closest to in the Frobenius norm. However, it also ensures that has a -factor structure, that is can be written as
where is the identity matrix and has rows and columns. is often referred to as the factor loading matrix. This problem primarily arises when a factor model is used to describe a multivariate time series or collateralized debt obligations. In this model and are vectors of independent random variables having zero mean and unit variance, with and independent of each other, and with diagonal. In the case of modelling debt obligations can, for example, model the equity returns of different companies of a portfolio where describes factors influencing all companies, in contrast to the elements of having only an effect on the equity of the corresponding company. With this model the complex behaviour of a portfolio, with potentially thousands of equities, is captured by looking at the major factors driving the behaviour.
The number of factors usually chosen is a lot smaller than , perhaps between and , yielding a large reduction in the complexity. The number of the factors, , which yields a matrix such that is within a required tolerance can also be determined, by experimenting with the input and comparing the norms. |
2.2 Regression
2.2.1 Aims of regression modelling
In regression analysis the relationship between one specific random variable, the dependent or response variable, and one or more known variables, called the independent variables or covariates, is studied. This relationship is represented by a mathematical model, or an equation, which associates the dependent variable with the independent variables, together with a set of relevant assumptions. The independent variables are related to the dependent variable by a function, called the regression function, which involves a set of unknown parameters. Values of the parameters which give the best fit for a given set of data are obtained; these values are known as the estimates of the parameters.
The reasons for using a regression model are twofold. The first is to obtain a
description of the relationship between the variables as an indicator of possible causality. The second reason is to
predict the value of the dependent variable from a set of values of the independent variables. Accordingly, the most usual statistical problems involved in regression analysis are:
| (i) |
to obtain best estimates of the unknown regression parameters; |
| (ii) |
to test hypotheses about these parameters; |
| (iii) |
to determine the adequacy of the assumed model; and |
| (iv) |
to verify the set of relevant assumptions. |
2.2.2 Regression models and designed experiments
One application of regression models is in the analysis of experiments. In this case the model relates the dependent variable to qualitative independent variables known as
factors. Factors may take a number of different values known as
levels. For example, in an experiment in which one of four different treatments is applied, the model will have one factor with four levels. Each level of the factor can be represented by a dummy variable taking the values
or
. So in the example there are four dummy variables
, for
, such that:
along with a variable for the mean
:
If there were
observations the data would be:
When dummy variables are used it is common for the model not to be of full rank. In the case above, the model would not be of full rank because
This means that the effect of cannot be distinguished from the combined effect of and . This is known as aliasing. In this situation, the aliasing can be deduced from the experimental design and as a result the model to be fitted; in such situations it is known as intrinsic aliasing. In the example above no matter how many times each treatment is replicated (other than ) the aliasing will still be present. If the aliasing is due to a particular dataset to which the model is to be fitted then it is known as extrinsic aliasing. If in the example above observation was missing then the term would also be aliased. In general intrinsic aliasing may be overcome by changing the model, e.g., remove or from the model, or by introducing constraints on the parameters, e.g., .
If aliasing is present then there will no longer be a unique set of least squares estimates for the parameters of the model but the fitted values will still have a unique estimate. Some linear functions of the parameters will also have unique estimates; these are known as estimable functions. In the example given above the functions () and () are both estimable.
2.2.3 Selecting the regression model
In many situations there are several possible independent variables, not all of which may be needed in the model. In order to select a suitable set of independent variables, two basic approaches can be used.
| (a) |
All possible regressions
In this case all the possible combinations of independent variables are fitted and the one considered the best selected. To choose the best, two conflicting criteria have to be balanced. One is the fit of the model which will improve as more variables are added to the model. The second criterion is the desire to have a model with a small number of significant terms. Depending on how the model is fit, statistics such as , which gives the proportion of variation explained by the model, and , which tries to balance the size of the residual sum of squares against the number of terms in the model, can be used to aid in the choice of model. |
| (b) |
Stepwise model building
In stepwise model building the regression model is constructed recursively, adding or deleting the independent variables one at a time. When the model is built up the procedure is known as forward selection. The first step is to choose the single variable which is the best predictor. The second independent variable to be added to the regression equation is that which provides the best fit in conjunction with the first variable. Further variables are then added in this recursive fashion, adding at each step the optimum variable, given the other variables already in the equation. Alternatively, backward elimination can be used. This is when all variables are added and then the variables dropped one at a time, the variable dropped being the one which has the least effect on the fit of the model at that stage. There are also hybrid techniques which combine forward selection with backward elimination. |
2.3 Linear Regression Models
When the regression model is linear in the parameters (but not necessarily in the independent variables), then the regression model is said to be linear; otherwise the model is classified as nonlinear.
The most elementary form of regression model is the
simple linear regression of the dependent variable,
, on a single independent variable,
, which takes the form
where
is the expected or average value of
and
and
are the parameters whose values are to be estimated, or, if the regression is required to pass through the origin (i.e., no constant term),
where
is the only unknown parameter.
An extension of this is
multiple linear regression in which the dependent variable,
, is regressed on the
(
) independent variables,
, which takes the form
where
and
are the unknown parameters. Multiple linear regression models test include factors are sometimes known as
General Linear (Regression) Models.
A special case of multiple linear regression is polynomial linear regression, in which the independent variables are in fact powers of the same single variable (i.e., , for ).
In this case, the model defined by
(3) becomes
There are a great variety of
nonlinear regression models; one of the most common is
exponential regression, in which the equation may take the form
It should be noted that equation
(4) represents a
linear regression, since even though the equation is not linear in the independent variable,
, it is linear in the parameters
, whereas the regression model of equation
(5) is
nonlinear, as it is nonlinear in the parameters (
,
and
).
2.3.1 Fitting the regression model – least squares estimation
One method used to determine values for the parameters is, based on a given set of data, to minimize the sums of squares of the differences between the observed values of the dependent variable and the values predicted by the regression equation for that set of data – hence the term
least squares estimation. For example, if a regression model of the type given by equation
(3), namely
where
for all observations, is to be fitted to the
data points
such that
where
are unknown independent random errors with
and
,
being a constant, then the method used is to calculate the estimates of the regression parameters
by minimizing
If the errors do not have constant variance, i.e.,
then
weighted least squares estimation is used in which
is minimized. For a more complete discussion of these least squares regression methods, and details of the mathematical techniques used, see
Draper and Smith (1985) or
Kendall and Stuart (1973).
2.3.2 Computational methods for least squares regression
Let
be the
by
matrix of independent variables and
be the vector of values for the dependent variable. To find the least squares estimates of the vector of parameters,
, the
decomposition of
is found, i.e.,
where
,
being a
by
upper triangular matrix, and
an
by
orthogonal matrix. If
is of full rank then
is the solution to
where
and
is the first
rows of
. If
is not of full rank, a solution is obtained by means of a singular value decomposition (SVD) of
,
where
is a
by
diagonal matrix with nonzero diagonal elements,
being the rank of
, and
and
are
by
orthogonal matrices. This gives the solution
being the first columns of and being the first columns of .
This will be only one of the possible solutions. Other estimates may be obtained by applying constraints to the parameters. If weighted regression with a vector of weights is required then both and are premultiplied by .
The method described above will, in general, be more accurate than methods based on forming (
), (or a scaled version), and then solving the equations
2.3.3 Examining the fit of the model
Having fitted a model two questions need to be asked: first, ‘are all the terms in the model needed?’ and second, ‘is there some systematic lack of fit?’. To answer the first question either confidence intervals can be computed for the parameters or
-tests can be calculated to test hypotheses about the regression parameters – for example, whether the value of the parameter,
, is significantly different from a specified value,
(often zero). If the estimate of
is
and its standard error is
then the
-statistic is
It should be noted that both the tests and the confidence intervals may not be independent. Alternatively
-tests based on the residual sums of squares for different models can also be used to test the significance of terms in the model. If model
, giving residual sum of squares
with degrees of freedom
, is a sub-model of model
, giving residual sum of squares
with degrees of freedom
, i.e., all terms in model
are also in model
, then to test if the extra terms in model
are needed the
-statistic
may be used. These tests and confidence intervals require the additional assumption that the errors,
, are Normally distributed.
To check for systematic lack of fit the residuals, , where is the fitted value, should be examined. If the model is correct then they should be random with no discernible pattern. Due to the way they are calculated the residuals do not have constant variance. Now the vector of fitted values can be written as a linear combination of the vector of observations of the dependent variable, , . The variance-covariance matrix of the residuals is then , being the identity matrix. The diagonal elements of , , can therefore be used to standardize the residuals. The are a measure of the effect of the th observation on the fitted model and are sometimes known as leverages.
If the observations were taken serially the residuals may also be used to test the assumption of the independence of the and hence the independence of the observations.
2.3.4 Ridge regression
When data on predictor variables
are multicollinear,
ridge regression models provide an alternative to variable selection in the multiple regression model. In the ridge regression case, parameter estimates in the linear model are found by penalised least squares:
where the value of the ridge parameter
controls the trade-off between the goodness-of-fit and smoothness of a solution.
2.4 Robust Estimation
Least squares regression can be greatly affected by a small number of unusual, atypical, or extreme observations. To protect against such occurrences, robust regression methods have been developed. These methods aim to give less weight to an observation which seems to be out of line with the rest of the data given the model under consideration. That is to seek to bound the influence. For a discussion of influence in regression, see
Hampel et al. (1986) and
Huber (1981).
There are two ways in which an observation for a regression model can be considered atypical. The values of the independent variables for the observation may be atypical or the residual from the model may be large.
The first problem of atypical values of the independent variables can be tackled by calculating weights for each observation which reflect how atypical it is, i.e., a strongly atypical observation would have a low weight. There are several ways of finding suitable weights; some are discussed in
Hampel et al. (1986).
The second problem is tackled by bounding the contribution of the individual
to the criterion to be minimized. When minimizing
(7) a set of linear equations is formed, the solution of which gives the least squares estimates. The equations are
These equations are replaced by
where
is the variance of the
, and
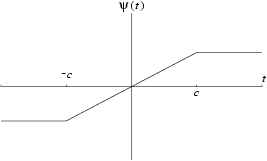
is a suitable function which down weights large values of the standardized residuals
. There are several suggested forms for
, one of which is Huber's function,
The solution to
(8) gives the
-estimates of the regression coefficients. The weights can be included in
(8) to protect against both types of extreme value. The parameter
can be estimated by the median absolute deviations of the residuals or as a solution to, in the unweighted case,
where
is a suitable function and
is a constant chosen to make the estimate unbiased.
is often chosen to be
where
is given in
(9). Another form of robust regression is to minimize the sum of absolute deviations, i.e.,
For details of robust regression, see
Hampel et al. (1986) and
Huber (1981).
Robust regressions using least absolute deviations can be computed using functions in
Chapter e02.
2.5 Generalized Linear Models
Generalized linear models are an extension of the general linear regression model discussed above. They allow a wide range of models to be fitted. These included certain nonlinear regression models, logistic and probit regression models for binary data, and log-linear models for contingency tables. A generalized linear model consists of three basic components:
| (a) |
A suitable distribution for the dependent variable . The following distributions are common:
| (i) |
Normal |
| (ii) |
binomial |
| (iii) |
Poisson |
| (iv) |
gamma |
In addition to the obvious uses of models with these distributions it should be noted that the Poisson distribution can be used in the analysis of contingency tables while the gamma distribution can be used to model variance components. The effect of the choice of the distribution is to define the relationship between the expected value of , , and its variance and so a generalized linear model with one of the above distributions may be used in a wider context when that relationship holds. |
| (b) |
A linear model , is known as a linear predictor. |
| (c) |
A link function between the expected value of and the linear predictor, . The following link functions are available:
For the binomial distribution , observing out of :
| (i) |
logistic link: ; |
| (ii) |
probit link: ; |
| (iii) |
complementary log-log: . |
For the Normal, Poisson, and gamma distributions:
| (i) |
exponent link: , for a constant ; |
| (ii) |
identity link: ; |
| (iii) |
log link: ; |
| (iv) |
square root link: ; |
| (v) |
reciprocal link: . |
For each distribution there is a canonical link. For the canonical link there exist sufficient statistics for the parameters. The canonical links are:
| (i) |
Normal – identity; |
| (ii) |
binomial – logistic; |
| (iii) |
Poisson – logarithmic; |
| (iv) |
gamma – reciprocal. |
For the general linear regression model described above the three components are:
| (i) |
Distribution – Normal; |
| (ii) |
Linear model – ; |
| (iii) |
Link – identity. |
|
The model is fitted by maximum likelihood; this is equivalent to least squares in the case of the Normal distribution. The residual sums of squares used in regression models is generalized to the concept of deviance. The deviance is the logarithm of the ratio of the likelihood of the model to the full model in which , where is the estimated value of . For the Normal distribution the deviance is the residual sum of squares. Except for the case of the Normal distribution with the identity link, the and -tests based on the deviance are only approximate; also the estimates of the parameters will only be approximately Normally distributed. Thus only approximate - or -tests may be performed on the parameter values and approximate confidence intervals computed.
The estimates are found by using an iterative weighted least squares procedure. This is equivalent to the Fisher scoring method in which the Hessian matrix used in the Newton–Raphson method is replaced by its expected value. In the case of canonical links the Fisher scoring method and the Newton–Raphson method are identical. Starting values for the iterative procedure are obtained by replacing the by in the appropriate equations.
2.6 Linear Mixed Effects Regression
In a standard linear model the independent (or explanatory) variables are assumed to take the same set of values for all units in the population of interest. This type of variable is called fixed. In contrast, an independent variable that fluctuates over the different units is said to be random. Modelling a variable as fixed allows conclusions to be drawn only about the particular set of values observed. Modelling a variable as random allows the results to be generalized to the different levels that may have been observed. In general, if the effects of the levels of a variable are thought of as being drawn from a probability distribution of such effects then the variable is random. If the levels are not a sample of possible levels then the variable is fixed. In practice many qualitative variables can be considered as having fixed effects and most blocking, sampling design, control and repeated measures as having random effects.
In a general linear regression model, defined by
| where |
is a vector of observations on the dependent variable, |
| |
is an by design matrix of independent variables, |
| |
is a vector of unknown parameters, |
| and |
is a vector of , independent and identically distributed, unknown errors, with
,
|
there are
fixed effects (the
) and a single
random effect (the error term
).
An extension to the general linear regression model that allows for additional
random effects is the linear mixed effects regression model, (sometimes called the variance components model). One parameterisation of a linear mixed effects model is
| where |
is a vector of observations on the dependent variable, |
| |
is an by design matrix of fixed independent variables, |
| |
is a vector of unknown fixed effects, |
| |
is an by design matrix of random independent variables, |
| |
is a vector of length of unknown random effects, |
| |
is a vector of length of unknown random errors, |
and
and
are normally distributed with expectation zero and variance / covariance matrix defined by
The functions currently available in this chapter are restricted to cases where
,
is the identity matrix and is a diagonal matrix. Given this restriction the random variables, , can be subdivided into groups containing one or more variables. The variables in the th group are identically distributed with expectation zero and variance . The model therefore contains three sets of unknowns, the fixed effects, , the random effects, , and a vector of variance components, , with . Rather than work directly with and the full likelihood function, is replaced by and the profiled likelihood function is used instead.
The model parameters are estimated using an iterative method based on maximizing either the restricted (profiled) likelihood function or the (profiled) likelihood functions. Fitting the model via restricted maximum likelihood involves maximizing the function
Whereas fitting the model via maximum likelihood involves maximizing
Once the final estimates for
have been obtained, the value of
is given by
Case weights, , can be incorporated into the model by replacing and with and respectively, for a diagonal weight matrix .
2.7 Quantile Regression
Quantile regression is related to least squares regression in that both are interested in studying the relationship between a response variable and one or more independent or explanatory variables. However, whereas least squares regression is concerned with modelling the conditional mean of the dependent variable, quantile regression models the conditional th quantile of the dependent variable, for some value of . So, for example, would be the median.
Throughout this section we will be making use of the following definitions:
| (a) |
If is a real valued random variable with distribution function and density function , such that
then the th quantile, , can be defined as
|
| (b) |
denotes an indicator function taking the value if the logical expression is true and 0 otherwise, e.g., if and if . |
| (c) |
denotes a vector of observations on the dependent (or response) variable, .
|
| (d) |
denotes an matrix of explanatory or independent variables, often referred to as the design matrix, and denotes a column vector of length which holds the th row of . |
2.7.1 Finding a sample quantile as an optimization problem
Consider the piecewise linear loss function
The minimum of the expectation
can be obtained by using the integral rule of Leibnitz to differentiate with respect to
and then setting the result to zero, giving
hence
when the solution is unique. If the solution is not unique then there exists a range of quantiles, each of which is equally valid. Taking the smallest value of such a range ensures that the empirical quantile function is left-continuous. Therefore obtaining the
th quantile of a distribution
can be achieved by minimizing the expected value of the loss function
.
This idea of obtaining the quantile by solving an optimization problem can be extended to finding the
th sample quantile. Given a vector of
observed values,
, from some distribution the empirical distribution function,
provides an estimate of the unknown distribution function
giving an expected loss of
and therefore the problem of finding the
th sample quantile,
, can be expressed as finding the solution to the problem
effectively replacing the operation of sorting, usually required when obtaining a sample quantile, with an optimization.
2.7.2 From least squares to quantile regression
Given the vector
it is a well known result that the sample mean,
, solves the least squares problem
This result leads to least squares regression where, given design matrix
and defining the conditional mean of
as
, an estimate of
is obtained from the solution to
Quantile regression can be derived in a similar manner by specifying the
th conditional quantile as
and estimating
as the solution to
2.7.3 Quantile regression as a linear programming problem
By introducing
slack variables,
and
, the quantile regression minimization problem,
(10), can be expressed as a linear programming (LP) problem, with primal and associated dual formulations
| (a) |
Primal form
where is a vector of length , where each element is .
If denotes the th residual, , then the slack variables, , can be thought as corresponding to the absolute value of the positive and negative residuals respectively with
|
| (b) |
Dual form
The dual formulation of (11) is given by
which, on setting , is equivalent to
|
| (c) |
Canonical form
Linear programming problems are often described in a standard way, called the canonical form. The canonical form of an LP problem is
Letting denote a vector of zeros denote a vector of arbitarily small or large values, denote the identity matrix, denote the row vector constructed by concatenating the elements of vector to the elements of vector and denote the matrix constructed by concatenating the columns of matrix onto the columns of matrix then setting
gives the quantile regression LP problem as described in (11). |
Once expressed as an LP problem the parameter estimates
can be obtained in a number of ways, for example via the inertia-controlling method of
Gill and Murray (1978) (see
nag_opt_lp (e04mfc)), the simplex method or an interior point method as used by
nag_regsn_quant_linear_iid (g02qfc) and
nag_regsn_quant_linear (g02qgc).
2.7.4 Estimation of the covariance matrix
Koenker (2005) shows that the limiting covariance matrix of
is of the form of a Huber Sandwich. Therefore, under the assumption of Normally distributed errors
where
and
denotes the conditional density of the response
evaluated at the
th conditional quantile.
More generally, the asymptotic covariance matrix for
has blocks defined by
Under the assumption of independent, identically distributed (iid) errors,
(13) simplifies to
where
is the sparsity function, given by
a similar simplification occurs with
(14).
In cases where the assumption of iid errors does not hold,
Powell (1991) suggests using a kernel estimator of the form
for some bandwidth parameter
satisfying
and
and
Hendricks and Koenker (1991) suggest a method based on an extension of the idea of sparsity.
Rather than use an asymptotic estimate of the covariance matrix, it is also possible to use bootstrapping. Roughly speaking the original data is resampled and a set of parameter estimates obtained from each new sample. A sample covariance matrix is then constructed from the resulting matrix of parameter estimates.
2.8 Latent Variable Methods
Regression by means of projections to latent structures also known as partial least squares, is a latent variable linear model suited to data for which:
- the number of -variables is high compared to the number of observations;
- -variables and/or -variables are multicollinear.
Latent variables are linear combinations of -variables that explain variance in and -variables. These latent variables, known as factors, are extracted iteratively from the data. A choice of the number of factors to include in a model can be made by considering diagnostic statistics such as the variable influence on projections (VIP).
2.9 LARS, LASSO and Forward Stagewise Regression
Least Angle Regression (LARS), Least Absolute Shrinkage Selection Operator (LASSO) and forward stagewise regression are three closely related regression techniques. Of the three, only LASSO has an easily accessible mathematical description suitable for being summarised here. A full description of the all three methods and the relationship between them can be found in
Efron et al. (2004) and the references there in.
Given a vector of
observed values,
and an
design matrix
, where the
th column of
, denoted
, is a vector of length
representing the
th independent variable
, standardized such that
, and
and a set of model parameters
to be estimated from the observed values, the LASSO model of
Tibshirani (1996) is given by
for a given value of
, where
. The positive LASSO model is the same as the standard LASSO model, given above, with the added constraint that
Rather than solve
(15) for a given value of
,
Efron et al. (2004) defined an algorithm that returns a full solution path for all possible values of
. It turns out that this path is piecewise linear with a finite number of pieces, denoted
, corresponding to
sets of parameter estimates.
3 Recommendations on Choice and Use of Available Functions
3.1 Correlation
3.1.1 Product-moment correlation
Let
be the sum of squares of deviations from the mean,
, for the variable
for a sample of size
, i.e.,
and let
be the cross-products of deviations from the means,
and
, for the variables
and
for a sample of size
, i.e.,
Then the sample covariance of
and
is
and the product-moment correlation coefficient is
nag_sum_sqs_update (g02btc) updates the sample sums of squares and cross-products and deviations from the means by the addition/deletion of a (weighted) observation.
nag_sum_sqs (g02buc) computes the sample sums of squares and cross-products deviations from the means (optionally weighted). The output from multiple calls to
nag_sum_sqs (g02buc) can be combined via a call to
nag_sum_sqs_combine (g02bzc), allowing large datasets to be summarised across multiple processing units.
nag_sum_sqs_update (g02btc) updates the sample sums of squares and cross-products and deviations from the means by the addition/deletion of a (weighted) observation.
nag_cov_to_corr (g02bwc) computes the product-moment correlation coefficients from the sample sums of squares and cross-products of deviations from the means.
The three functions compute only the upper triangle of the correlation matrix which is stored in a one-dimensional array in packed form.
nag_corr_cov (g02bxc) computes both the (optionally weighted) covariance matrix and the (optionally weighted) correlation matrix. These are returned in two-dimensional arrays. (Note that
nag_sum_sqs_update (g02btc) and
nag_sum_sqs (g02buc) can be used to compute the sums of squares from zero.)
3.1.2 Product-moment correlation with missing values
If there are missing values then
nag_sum_sqs (g02buc) and
nag_corr_cov (g02bxc), as described above, will allow casewise deletion by you giving the observation zero weight (compared with unit weight for an otherwise unweighted computation).
3.1.3 Nonparametric correlation
nag_ken_spe_corr_coeff (g02brc) computes Kendall and/or Spearman nonparametric rank correlation coefficients. The function allows for a subset of variables to be selected and for observations to be excluded from the calculations if, for example, they contain missing values.
3.1.4 Partial correlation
nag_partial_corr (g02byc) computes a matrix of partial correlation coefficients from the correlation coefficients or variance-covariance matrix returned by
nag_corr_cov (g02bxc).
3.1.5 Robust correlation
nag_robust_m_corr_user_fn (g02hlc) and
nag_robust_m_corr_user_fn_no_derr (g02hmc) compute robust estimates of the variance-covariance matrix by solving the equations
and
as described in
Section 2.1.4 for user-supplied functions
and
. Two options are available for
, either
for all
or
.
nag_robust_m_corr_user_fn_no_derr (g02hmc) requires only the function
and
to be supplied while
nag_robust_m_corr_user_fn (g02hlc) also requires their derivatives.
In general
nag_robust_m_corr_user_fn (g02hlc) will be considerably faster than
nag_robust_m_corr_user_fn_no_derr (g02hmc) and should be used if derivatives are available.
nag_robust_corr_estim (g02hkc) computes a robust variance-covariance matrix for the following functions:
and
for constants
,
and
.
These functions solve a minimax space problem considered by
Huber (1981). The values of
,
and
are calculated from the fraction of gross errors; see
Hampel et al. (1986) and
Huber (1981).
To compute a correlation matrix from the variance-covariance matrix
nag_cov_to_corr (g02bwc) may be used.
3.1.6 Nearest correlation matrix
Four functions are provided to calculate a nearest correlation matrix. The choice of function will depend on what definition of ‘nearest’ is required and whether there is any particular structure desired in the resulting correlation matrix.
nag_nearest_correlation (g02aac) computes the nearest correlation matrix in the Frobenius norm, using the method of
Qi and Sun (2006).
nag_nearest_correlation_bounded (g02abc) uses an extension of the method implemented in
nag_nearest_correlation (g02aac) allowing for the row and column weighted Frobenius norm to be used as well as bounds on the eigenvalues of the resulting correlation matrix to be specified.
nag_nearest_correlation_k_factor (g02aec) computes the factor loading matrix, allowing a correlation matrix with a
-factor structure to be computed.
nag_nearest_correlation_h_weight (g02ajc) again computes the nearest correlation matrix in the Frobenius norm, but allows for element-wise weighting as well as bounds on the eigenvalues.
3.2 Regression
3.2.1 Simple linear regression
Two functions are provided for simple linear regression. The function
nag_simple_linear_regression (g02cac) calculates the parameter estimates for a simple linear regression with or without a constant term. The function
nag_regress_confid_interval (g02cbc) calculates fitted values, residuals and confidence intervals for both the fitted line and individual observations. This function produces the information required for various regression plots.
3.2.2 Ridge regression
nag_regsn_ridge_opt (g02kac) calculates a ridge regression, optimizing the ridge parameter according to one of four prediction error criteria.
nag_regsn_ridge (g02kbc) calculates ridge regressions for a given set of ridge parameters.
3.2.3 Polynomial regression and nonlinear regression
No functions are currently provided in this chapter for polynomial regression. If you wish to perform polynomial regressions you have three alternatives: you can use the multiple linear regression functions,
nag_regsn_mult_linear (g02dac), with a set of independent variables which are in fact simply the same single variable raised to different powers, or you can use the function
nag_dummy_vars (g04eac) to compute orthogonal polynomials which can then be used with
nag_regsn_mult_linear (g02dac), or you can use the functions in
Chapter e02 (Curve and Surface Fitting) which fit polynomials to sets of data points using the techniques of orthogonal polynomials. This latter course is to be preferred, since it is more efficient and liable to be more accurate, but in some cases more statistical information may be required than is provided by those functions, and it may be necessary to use the functions of this chapter.
More general nonlinear regression models may be fitted using the optimization functions in
Chapter e04, which contains functions to minimize the function
where the regression parameters are the variables of the minimization problem.
3.2.4 Multiple linear regression – general linear model
nag_regsn_mult_linear (g02dac) fits a general linear regression model using the
method and an SVD if the model is not of full rank. The results returned include: residual sum of squares, parameter estimates, their standard errors and variance-covariance matrix, residuals and leverages. There are also several functions to modify the model fitted by
nag_regsn_mult_linear (g02dac) and to aid in the interpretation of the model.
nag_regsn_mult_linear_addrem_obs (g02dcc) adds or deletes an observation from the model.
nag_regsn_mult_linear_newyvar (g02dgc) fits the regression to a new dependent variable, i.e., keeping the same independent variables.
nag_regsn_mult_linear_tran_model (g02dkc) calculates the estimates of the parameters for a given set of constraints, (e.g., parameters for the levels of a factor sum to zero) for a model which is not of full rank and the SVD has been used.
nag_regsn_mult_linear_est_func (g02dnc) calculates the estimate of an estimable function and its standard error.
Note: nag_regsn_mult_linear_add_var (g02dec) also allows you to initialize a model building process and then to build up the model by adding variables one at a time.
3.2.5 Selecting regression models
To aid the selection of a regression model the following functions are available.
nag_all_regsn (g02eac) computes the residual sums of squares for all possible regressions for a given set of dependent variables. The function allows some variables to be forced into all regressions.
nag_cp_stat (g02ecc) computes the values of
and
from the residual sums of squares as provided by
nag_all_regsn (g02eac).
nag_step_regsn (g02eec) enables you to fit a model by forward selection. You may call
nag_step_regsn (g02eec) a number of times. At each call the function will calculate the changes in the residual sum of squares from adding each of the variables not already included in the model, select the variable which gives the largest change and then if the change in residual sum of squares meets the given criterion will add it to the model.
nag_full_step_regsn (g02efc) uses a full stepwise selection to choose a subset of the explanatory variables. The method repeatedly applies a forward selection step followed by a backward elimination step until neither step updates the current model.
3.2.6 Residuals
nag_regsn_std_resid_influence (g02fac) computes the following standardized residuals and measures of influence for the residuals and leverages produced by
nag_regsn_mult_linear (g02dac):
| (i) |
Internally studentized residual; |
| (ii) |
Externally studentized residual; |
| (iii) |
Cook's statistic; |
| (iv) |
Atkinson's statistic. |
nag_durbin_watson_stat (g02fcc) computes the Durbin–Watson test statistic and bounds for its significance to test for serial correlation in the errors,
.
3.2.7 Robust regression
For robust regression using
-estimates instead of least squares the function
nag_robust_m_regsn_estim (g02hac) will generally be suitable.
nag_robust_m_regsn_estim (g02hac) provides a choice of four
-functions (Huber's, Hampel's, Andrew's and Tukey's) plus two different weighting methods and the option not to use weights. If other weights or different
-functions are needed the function
nag_robust_m_regsn_user_fn (g02hdc) may be used.
nag_robust_m_regsn_user_fn (g02hdc) requires you to supply weights, if required, and also functions to calculate the
-function and, optionally, the
-function.
nag_robust_m_regsn_wts (g02hbc) can be used in calculating suitable weights. The function
nag_robust_m_regsn_param_var (g02hfc) can be used after a call to
nag_robust_m_regsn_user_fn (g02hdc) in order to calculate the variance-covariance estimate of the estimated regression coefficients.
For robust regression, using least absolute deviation,
nag_lone_fit (e02gac) can be used.
3.2.8 Generalized linear models
There are four functions for fitting generalized linear models. The output includes: the deviance, parameter estimates and their standard errors, fitted values, residuals and leverages.
While
nag_glm_normal (g02gac) can be used to fit linear regression models (i.e., by using an identity link) this is not recommended as
nag_regsn_mult_linear (g02dac) will fit these models more efficiently.
nag_glm_poisson (g02gcc) can be used to fit log-linear models to contingency tables.
In addition to the functions to fit the models there is one function to predict from the fitted model and two functions to aid interpretation when the fitted model is not of full rank, i.e., aliasing is present.
nag_glm_predict (g02gpc) computes a predicted value and its associated standard error based on a previously fitted generalized linear model.
nag_glm_tran_model (g02gkc) computes parameter estimates for a set of constraints, (e.g., sum of effects for a factor is zero), from the SVD solution provided by the fitting function.
nag_glm_est_func (g02gnc) calculates an estimate of an estimable function along with its standard error.
3.2.9 Linear mixed effects regression
There are four functions for fitting linear mixed effects regression.
nag_reml_mixed_regsn (g02jac) and
nag_reml_hier_mixed_regsn (g02jdc) uses restricted maximum likelihood (REML) to fit the model.
For all functions the output includes: either the maximum likelihood or restricted maximum likelihood and the fixed and random parameter estimates, along with their standard errors. Whilst it is possible to fit a hierachical model using
nag_reml_mixed_regsn (g02jac) or
nag_ml_mixed_regsn (g02jbc),
nag_reml_hier_mixed_regsn (g02jdc) and
nag_ml_hier_mixed_regsn (g02jec) allow the model to be specified in a more intuitive way.
nag_hier_mixed_init (g02jcc) must be called prior to calling
nag_reml_hier_mixed_regsn (g02jdc) or
nag_ml_hier_mixed_regsn (g02jec).
As the estimates of the variance components are found using an iterative procedure initial values must be supplied for each . In all four functions you can either specify these initial values, or allow the function to calculate them from the data using minimum variance quadratic unbiased estimation (MIVQUE0). Setting the maximum number of iterations to zero in any of the functions will return the corresponding likelihood, parameter estimates and standard errors based on these initial values.
3.2.10 Linear quantile regression
Two functions are provided for performing linear quantile regression,
nag_regsn_quant_linear_iid (g02qfc) and
nag_regsn_quant_linear (g02qgc). Of these,
nag_regsn_quant_linear_iid (g02qfc) provides a simplified interface to
nag_regsn_quant_linear (g02qgc), where many of the input parameters have been given default values and the amount of output available has been reduced.
Prior to calling
nag_regsn_quant_linear (g02qgc) the optional argument array must be initialized by calling
nag_g02_opt_set (g02zkc) with
optstr set to
Initialize. Once these arrays have been initialized
nag_g02_opt_get (g02zlc) can be called to query the value of an optional argument.
3.2.11 Partial Least Squares (PLS)
nag_pls_orth_scores_svd (g02lac) calculates a nonlinear, iterative PLS by using singular value decomposition.
nag_pls_orth_scores_wold (g02lbc) calculates a nonlinear, iterative PLS by using Wold's method.
nag_pls_orth_scores_fit (g02lcc) calculates parameter estimates for a given number of PLS factors.
nag_pls_orth_scores_pred (g02ldc) calculates predictions given a PLS model.
3.2.12 LARS, LASSO and Forward Stagewise Regression
Two functions for fitting a LARS, LASSO or forward stagewise regression are supplied:
nag_lars (g02mac) and
nag_lars_xtx (g02mbc). The difference between the two functions is in the way that the data,
and
, are supplied. The first function,
nag_lars (g02mac) takes
and
directly, whereas
nag_lars_xtx (g02mbc) takes the data in the form of the cross-products:
,
and
. In most situations
nag_lars (g02mac) will be the recommended function as the full data tends to be available. However when there is a large number of observations (i.e.,
is large) it might be preferable to split the data into smaller blocks and process one block at a time. In such situations
nag_sum_sqs (g02buc) and
nag_sum_sqs_combine (g02bzc) can be used to construct the required cross-products and
nag_lars_xtx (g02mbc) called to fit the required model.
Both
nag_lars (g02mac) and
nag_lars_xtx (g02mbc) return
sets of parameter estimates, which, because of it's piecewise linear nature, define the full LARS, LASSO or forward stagewise regression solution path. However, parameter estimates are sometimes required at points along the solution path that differ from those returned by
nag_lars (g02mac) and
nag_lars_xtx (g02mbc), for example when performing a cross-validation.
nag_lars_param (g02mcc) will return the parameter estimates in such cases.
4 Functionality Index
| Computes the nearest correlation matrix using the method of Qi and Sun, | | |
| Generalized linear models, | | |
| Hierarchical mixed effects regression, | | |
| Least angle regression (includes LASSO), | | |
| Linear mixed effects regression, | | |
| Multiple linear regression/General linear model, | | |
| Non-parametric rank correlation (Kendall and/or Spearman): | | |
| casewise treatment of missing values, | | |
| Product-moment correlation, | | |
| Selecting regression model, | | |
| Simple linear regression, | | |
| Stepwise linear regression, | | |
5 Auxiliary Functions Associated with Library Function Arguments
6 Functions Withdrawn or Scheduled for Withdrawal
The following lists all those functions that have been withdrawn since Mark 23 of the Library or are scheduled for withdrawal at one of the next two marks.
7 References
Atkinson A C (1986) Plots, Transformations and Regressions Clarendon Press, Oxford
Churchman C W and Ratoosh P (1959) Measurement Definitions and Theory Wiley
Cook R D and Weisberg S (1982) Residuals and Influence in Regression Chapman and Hall
Draper N R and Smith H (1985) Applied Regression Analysis (2nd Edition) Wiley
Efron B, Hastie T, Johnstone I and Tibshirani R (2004) Least Angle Regression The Annals of Statistics (Volume 32) 2 407–499
Gill P E and Murray W (1978) Numerically stable methods for quadratic programming Math. Programming 14 349–372
Hammarling S (1985) The singular value decomposition in multivariate statistics SIGNUM Newsl. 20(3) 2–25
Hampel F R, Ronchetti E M, Rousseeuw P J and Stahel W A (1986) Robust Statistics. The Approach Based on Influence Functions Wiley
Hays W L (1970) Statistics Holt, Rinehart and Winston
Hendricks W and Koenker R (1991) Hierarchical spline models for conditional quantiles and the demand for electricity Journal of the Maerican Statistical Association 87 58–68
Huber P J (1981) Robust Statistics Wiley
Kendall M G and Stuart A (1973) The Advanced Theory of Statistics (Volume 2) (3rd Edition) Griffin
Koenker R (2005) Quantile Regression Econometric Society Monographs, Cambridge University Press, New York
McCullagh P and Nelder J A (1983) Generalized Linear Models Chapman and Hall
Powell J L (1991) Estimation of monotonic regression models under quantile restrictions Nonparametric and Semiparametric Methods in Econometrics Cambridge University Press, Cambridge
Qi H and Sun D (2006) A quadratically convergent Newton method for computing the nearest correlation matrix SIAM J. Matrix AnalAppl 29(2) 360–385
Searle S R (1971) Linear Models Wiley
Siegel S (1956) Non-parametric Statistics for the Behavioral Sciences McGraw–Hill
Tibshirani R (1996) Regression Shrinkage and Selection via the Lasso Journal of the Royal Statistics Society, Series B (Methodological) (Volume 58) 1 267–288
Weisberg S (1985) Applied Linear Regression Wiley